AI's Anglocentric Tokenization Tax
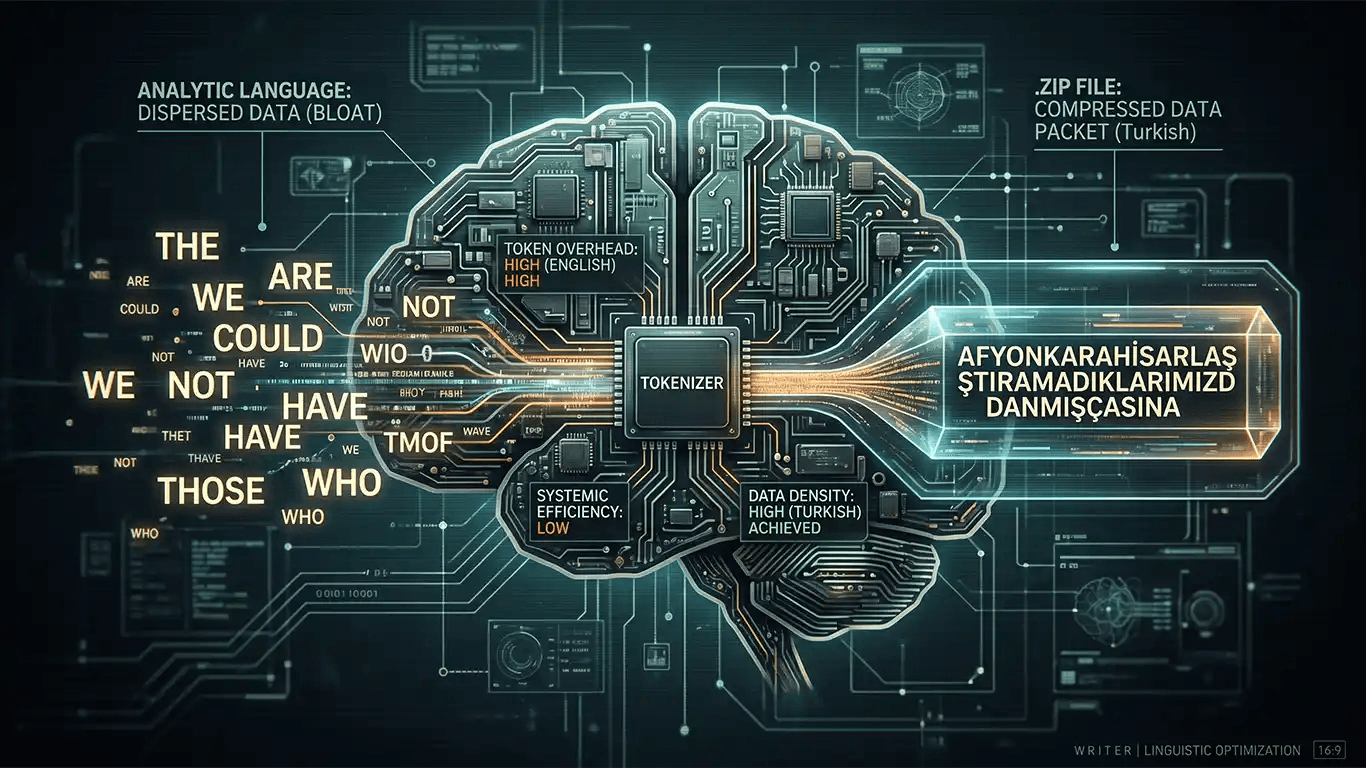
Look at the current state of "Natural Language Processing" and you will see a field blinded by its own Anglocentric hubris. Most developers treat English as the "gold standard" of logic; in reality, English is the legacy COBOL of linguistics: bloated, redundant, and reliant on a massive amount of "filler" to function. If we are looking for actual systemic efficiency in the age of Large Language Models (LLMs), we need to stop looking at English and start looking at agglutinative languages like Turkish. They are not just languages: they are high-density .zip files for human thought.
The Bloat of the Analytic "Standard"
English is an analytic language. It relies on word order and a trail of "helper" particles to convey even the most basic tense or mood. This is essentially the linguistic equivalent of a software update that requires ten different .dll files just to open a calculator app. When an LLM processes English, it is forced to burn "compute" on "of," "the," "would," and "have." These are empty calories: tokens that exist only to prop up a fragile grammatical structure (truly a masterpiece of "efficiency"!).
Compare this to Turkish. Turkish is agglutinative; it builds meaning by tacking functional suffixes onto a root. A single Turkish word can communicate what English requires a whole sentence to express.
Afyonkarahisarlaştıramadıklarımızdanmışçasına
This is not just a long word: it is a compressed data packet. It contains a root, a location, a causative, a negative, a capability, and a complex reported past tense. In the world of "tokenization," Turkish is a masterclass in high-density storage. While English-centric models are busy parsing five separate tokens to realize a subject is performing an action in the past, a properly optimized Turkish model has already extracted that entire context from a single "cluster."
The Tokenization "Tax"
The problem (and there is always a problem when corporate "visionaries" are involved) is that our current AI ecosystems are not built to respect this efficiency. Most tokenizers are trained on English-heavy datasets. They treat Turkish words like a generic "legacy system" they don't quite understand: hacking them into sub-word units that destroy the very "compression" that makes the language superior.
Instead of treating the suffix as a functional operator (the way a compiler treats a command), the tokenizer treats it as a "string of characters." This is a fundamental misunderstanding of the underlying mechanics. Big Tech is essentially trying to run a high-performance .zip file through a 1990s text editor and wondering why the "performance" isn't scaling. They would rather throw more GPUs at the problem (expensive "brute force") than actually refactor the way the model perceives the architecture of non-Indo-European thought...
The Pragmatic Reality
We are told that AI is becoming "more human," but it is actually just becoming more "American." By forcing every language to fit the analytic, word-heavy mold of English, we are losing the "semantic bandwidth" offered by agglutinative structures. If we actually cared about "optimization" (a word CEOs love to use while laying off the people who actually do the work!), we would be building models that leverage the mathematical precision of Turkish suffixes.
Instead, we will likely continue to see "optimized" models that are just slightly less bloated versions of their predecessors: still choking on the "of"s and "the"s of a language that was never designed for efficiency in the first place. The tech industry loves a "disruptive" solution, as long as it doesn't require them to actually learn how a different system works...